서론...
최근 Spring Boot 를 활용하여 백엔드 및 DevOps 포지션에서 3주간 서비스를 만드는 해커톤에 참여했다.
서비스 배포를 앞두고 배포후 발생할 수 있는 장애를 대비하는 과정에서 성능 개선의 필요성을 느꼈다.
하지만 백엔드 & DevOps 경험이 거의 없었기 때문에 무엇을 기준으로 성능을 개선하고, 어떤 부분을 개선해야할지 막막한 상황이었다.
분명 급하게 만든 만큼…성능을 개선할 부분이 많을 것으로 예측되지만…
추측으로 현재 어느정도의 성능인지도 모르고 개선을 이야기 하는 것도 말이 안되는 상황이었다. 무엇보다 팀원들의 리소스를 비효율적으로 사용할 수 없었다..
이런 상황에서 여러 기술 블로그를 참고하고 많은 고민을 한 후, 결국 JPA 쿼리 효율성을 먼저 개선하기로 결정했다.
이 과정에서 가장 처음으로 건드린 JPA N+1 문제에 대해 자세하게 알아본 과정을 풀어보고자 한다
문제를 찾아서
RDS에 로깅 시스템을 도입하는 과정에서 다음과 같은 log 를 발견할 수 있었다.
T19:58:14.682743Z 11 Query select ~~ from user ~
T19:58:14.684499Z 11 Query commit
T19:58:14.685790Z 11 Query SET autocommit=1
T19:58:14.687013Z 11 Query set session transaction read write
T19:58:14.693684Z 11 Query SET autocommit=0
T19:58:14.696351Z 11 Query select ~~
// 약 30줄...
T19:58:14.816092Z 11 Query select ~~
T19:58:14.817898Z 11 Query commit
T19:58:14.819097Z 11 Query SET autocommit=1
T19:58:16.217128Z 7사실 급하게 제작하고 배포하는 과정에서 JPA가 보여주는 SQL log 에 큰 신경을 쓰지 못하고 있었다.
3주 내내 당장 내일 클라이언트에 데이터를 보내는게 우선이었기 때문이기도 하다...
해당 부분에서 JPA 의 N+1 문제가 떠올랐다.N+1 문제에 대해 들어보고 개념만 인지하고 있었지만 실제 이를 개선하기 위해서 보다 자세하게 알아볼 필요가 있었다.
JPA N+1 이란?
JPA N+1 은 1개의 쿼리를 생각하고 설계 했지만 실제로는 N개의 쿼리가 더 발생하는 문제를 이야기 한다.
사실 직접 쿼리를 작성하면 발생하지 않지만, JPA 와 같이 자동화된 쿼리를 사용한다면 어쩔 수 없이 발생하게 되는 문제이다.
실제 JPA 연관 관계 조회 상황에서 문제를 확인하기 위해 아래와 같은 Entity를 구성했다.
이를 바탕으로 즉시로딩(EAGER) 및 지연로딩(LAZY) 상황에서 어떤 문제가 발생하는지 직접 검증하고자 했다.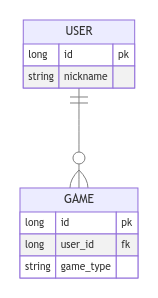
// user
@Entity
public class User {
//...
@OneToMany(mappedBy = "user")
private Set<Game> games = emptySet();
}
// game
@Entity
public class Game {
//...
@ManyToOne
private User user;
}N+ 1, 즉시 로딩(FetchType.EAGER)에서의 Case
// User
@OneToMany(mappedBy = "user", fetch = FetchType.EAGER)
private Set<Game> articles = emptySet()JPA 에서 FetchType.EAGER 를 사용하면 연관 관계에 있는 Entity도 함께 조회할 수 있다. 이 과정에서 JPA 구현체는 즉시 로딩을 최적화 하기 위해 가능하면 join 을 사용하여 쿼리를 날린다.
@Test
void eagerLoadingFindById() {
User user = expectedQueries(
() -> userRepository.findById(1L)
.orElseThrow()
);
System.out.println(user.getGames().size());
}실제 쿼리 로그를 보면 다음과 같다.
* === Expected Query Start ===
* Hibernate:
* select
* u1_0.id,
* g1_0.user_id,
* g1_0.id,
* g1_0.game_type,
* u1_0.nickname
* from
* users u1_0
* left join
* games g1_0
* on u1_0.id=g1_0.user_id
* where
* u1_0.id=?
* === Expected Query End ===
* 5다음과 같이 findById 를 사용하면 JPA 구현체가 최적화 과정에서 left outer join 을 사용한다. 따라서 이와 같은 상황에서는 JPA N+1 문제가 발생하지 않는다.
하지만, findAll 과 같이 최적화 하기 힘든 상황도 있다.
User 를 모두 조회하는 상황에서는 select u from user u; 의 쿼리를 사용한다. 하지만 JPA 에서는 현재 즉시 로딩을 통해 연관 관계의 Game 역시 조회해야 한다.
따라서 select 한 모든 User에 대해서 Game이 있는지 다시 쿼리를 즉시 날려야한다.
@Test
void eagerLoadingJpaFindAll() {
List<User> users = expectedQueries(
userRepository::findAll
);
users.forEach((user) -> System.out.println(user.getGames().size()));
}따라서 위 코드를 실행하면 다음과 같은 결과를 얻을 수 있다.
* === Expected Query Start ===
* Hibernate:
* select
* u1_0.id,
* u1_0.nickname
* from
* users u1_0
>>>>>>>>> 여기서부터 즉시 로딩으로 Game 추가 조회 <<<<<<<<<
* Hibernate:
* select
* g1_0.user_id,
* g1_0.id,
* g1_0.game_type
* from
* games g1_0
* where
* g1_0.user_id=?
>>>>>>>>> 여기에서 바로 위 쿼리가 User만큼 반복된다. <<<<<<<<<
* === Expected Query End ===결과를 일부 요약했지만 테스트에서는 10명의 User에 대해서 다시 Game에 10번의 조회가 발생했다.
즉,User 를 모두 검색하는 1개의 쿼리를 생각하고 설계한 부분에서 실제로 N회의 조회가 추가로 발생했다.
이러한 상황을 보고 N+1 문제라고 한다.
사실상 1번의 조회만 필요한 상황에 N+1회의 조회를 하는 것이 상당히 비효율적인 것 뿐 아니라,
지금은 User의 수를 10명으로 테스트한 상황이지만 User가 늘어나면 늘어날 수록 추가 쿼리 또한 늘어나게 된다.
따라서 이와 같은 문제로 인해 즉시 로딩을 사용하면 안된다고 한다.
N+ 1, 지연 로딩(FetchType.LAZY)에서의 Case
N+1의 문제가 발생하기 때문에 가능한 지연 로딩을 사용하도록 권장되고 있다.
그렇다고 해서 지연 로딩에서 N+1 문제가 발생하지 않는 것은 아니다.
// User
@OneToMany(mappedBy = "user", fetch = FetchType.LAZY)
private Set<Game> games = emptySet();JPA 에서 FetchType.LAZY 를 사용하면 연관 관계 대상(Lazy Loading 대상)은 프록시 객체로 저장된다.
이후 연관 관계 대상을 호출하거나 사용하는 경우, 이미 조회에 대한 쿼리는 마무리 되었기 때문에 join을 할 수 없고 결과적으로 이미 캐싱된 프록시 상태의 대상을 추가적으로 조회한다.
따라서 findAll 로 User 를 조회한다면 처음 조회에서는 N+1 문제가 발생하지 않게된다.
하지만, 결과적으로 User의 Game을 사용하려 한다면 이때 쿼리가 발생한다.
@Test
void LazyLoadingJpaFindAll() {
List<User> users = expectedQueries(
userRepository::findAll
);
users.forEach((user) -> System.out.println(user.getGames().size()));
}따라서 위 코드를 통해 아래와 같은 결과를 얻을 수 있다.
* === Expected Query Start ===
* Hibernate:
* select
* u1_0.id,
* u1_0.nickname
* from
* users u1_0
* === Expected Query End ===
>>>>>>>>> 여기서부터 조회 후 실제 사용하는 시점에 Game 추가 조회 <<<<<<<<<
* Hibernate:
* select
* g1_0.user_id,
* g1_0.id,
* g1_0.game_type
* from
* games g1_0
* where
* g1_0.user_id=?
>>>>>>>>> 위 과정에서 User 수 만큼 해당 쿼리가 반복된다. <<<<<<<<<사실 어떻게 보면 쿼리 시점에 N+1 이 발생하지 않지만, 결과적으로 지연되어 N회의 쿼리가 발생해 결과적으로 N+1 문제가 발생한다.
이는 JPA가 자동으로 만드는 쿼리가 아닌 JPQL로 직접 쿼리해도 같은 문제가 발생한다.select select (distinct) u from User u left join u.games
쿼리에서 left outer join 을 사용하여 데이터는 미리 가져오게 쿼리가 날아가지만, 결과적으로 Lazy 전략에 맞게 처리가된다.
이는 Eager 전략에서도 동일하게 처리가 된다.
실제 테스트에서도 자동으로 만들어지는 쿼리와 join 이 있냐 없냐 차이만 있지 실제로 동작에는 변화가 없다.
distinct 는 left outer join 과정에서 여러 game 으로 인해 user가 중복으로 나올 수 있다.
이러한 중복을 제거하기 위해 사용된다.
사실상 JPA 처리 과정에서 user를 중복하여 객체를 생성하지 않도록 중복을 처리하도록 한다.
그럼 어떻게 해결할 수 있을까?
N+1 은 결국 1번의 조회로 해결할 일을 1회 + N 회의 조회가 발생하여 생기는 문제이다.
실제 join 을 하더라도 JPA 로딩 전략등의 이유로 한번에 이를 읽어올 수 없었다.
그렇다면 이 문제를 해결하기 위해 1회의 조회에서 연관 관계에 있는 모든 Entity 를 한번에 영속화 하여 가져오면 해결할 수 있다.
지연 로딩과 fetch join
fetch join 은 SQL의 join 의 종류가 아닌 JPQL에서 성능 최적화를 위한 join 의 종류이다.
JPA Repository 에서 다음과 같이 사용할 수 있다.
@Query("select distinct u from User u left join fetch u.games")
List<User> findAllFetch();해당 Repository 를 다음과 같이 이용할 수 있다.
@Test
void Jpql_fetch_join_LazyLoadingJpaFindAll() {
List<User> users = expectedQueries(
userRepository::findAllFetch
);
users.forEach((user) -> System.out.println(user.getGames().size()));
}위 코드를 통해 아래와 같은 결과를 얻을 수 있다.
* === Expected Query Start ===
* Hibernate:
* select
* distinct u1_0.id,
* g1_0.user_id,
* g1_0.id,
* g1_0.game_type,
* u1_0.nickname
* from
* users u1_0
* left join
* games g1_0
* on u1_0.id=g1_0.user_id
* === Expected Query End ===
* 아래로 원하는 결과가 추가 쿼리 없이 나온다.일반적인 join 의 경우는 실제 질의하는 대상의 Entity인 User 만 select 하여 영속화했다.
그 후 연관 관계의 해당하는 Game 의 경우는 프록시로 넣어두고 이후 사용하는 순간에 영속화 하기 위해 추가 쿼리를 날렸다.
하지만, fetch join 의 결과를 보면 질의 대상의 Entity 뿐 아니라 join 대상 까지 한번에 select 했다.
그 결과 단 1회의 조회를 통해 원하는 모든 값을 가져올 수 있다.
지연 로딩과 @EntityGraph
위와 같이 fetch join 을 사용하여 N+1 문제를 해결할 수 있었다.
하지만, fetch join 을 사용하면 쿼리문을 JPQL로 하드코딩하는 단점이 존재한다.
JPQL로 하드코딩하면 휴먼 에러나 타입에 대한 에러가 발생해도 컴파일 타임에 알 수 없고 런타임이 되어야 알 수 있다.
이러한 상황을 최소화 하고자 한다면 @EntityGraph 를 사용할 수 있다.
@Override
@EntityGraph(attributePaths = {"games"}, type = EntityGraph.EntityGraphType.FETCH)
List<User> findAll();예시에서는 findAll 을 그대로 사용하기 위해 override 를 했다.
@Test
void entityGraphFindAll() {
List<User> users = expectedQueries(
userRepository::findAll
);
users.forEach((user) -> System.out.println(user.getGames().size()));
}위 코드를 통해 아래와 같은 결과를 얻을 수 있다.
* === Expected Query Start ===
* Hibernate:
* select
* distinct u1_0.id,
* g1_0.user_id,
* g1_0.id,
* g1_0.game_type,
* u1_0.nickname
* from
* users u1_0
* left join
* games g1_0
* on u1_0.id=g1_0.user_id
* === Expected Query End ===
* 아래로 원하는 결과가 추가 쿼리 없이 나온다.JPQL을 통해 직접 fetch join 을 사용하지 않았지만 그 결과가 같은 것을 확인할 수 있다.
EntityGraph 는 연관관계가 지연 로딩으로 된 경우 fetch 조인을 사용하여 쿼리를 한번에 해결할 수 있도록 지원한다.
마무리 하며...
실제 문제를 확인하고 JPA N+1 문제를 알아보고 이를 해결하는 방법에 대해 알아볼 수 있었다.
하지만 실제 서비스에 적용하는 과정에서 fetch join 이 만능 열쇠는 아니었다. 상황에 따라 BatchSize 와 같은 수단을 이용하게 되었는데 해당 부분은 다음 포스팅에 이어보고자 한다.
'Spring Boot' 카테고리의 다른 글
| Spock Framework 적용기 (0) | 2025.03.03 |
|---|
